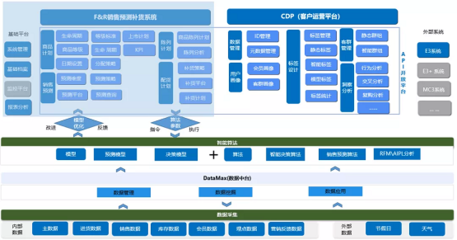
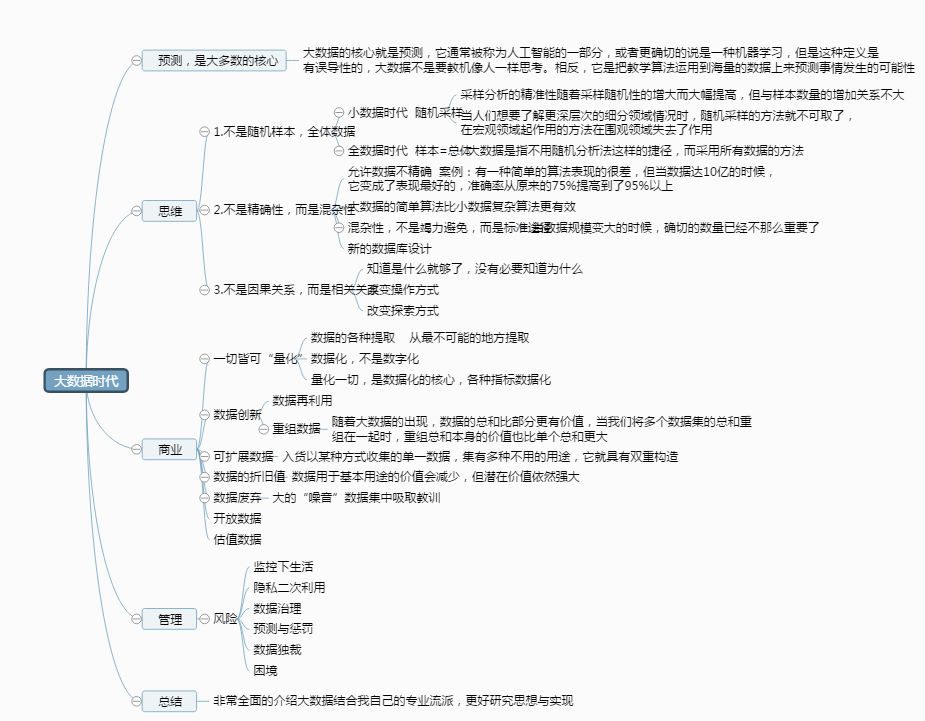
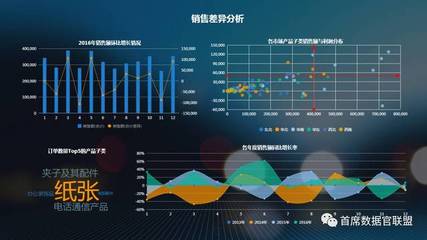
在當今這個數字化時代,“大數據”與“人工智能”已成為科技領域最核心、最引人注目的雙子星。兩者相輔相成,共同塑造著未來的圖景。如果說人工智能(AI)是模擬人類智能、實現自主決策與學習的“大腦”,那么大數據無疑是為這個“大腦”提供養料、驅動其進化與運行的“血液”和“燃料”。本文旨在深入探討大數據的概念、特性及其作為人工智能基石的關鍵作用。
一、 何為大數據:超越“大”的多元內涵
大數據并非單指數據量的龐大。國際公認,它具有“4V”或“5V”特征,這些特征共同定義了其本質:
- 體量(Volume):這是最直觀的特征。數據量從傳統的TB級躍升至PB、EB乃至ZB級。全球每天產生的數據量呈指數級增長,來自傳感器、社交媒體、交易記錄、物聯網設備等無數源頭。
- 速度(Velocity):數據生成、流動和處理的速度極快。例如,金融市場的實時交易數據、社交媒體的即時動態、自動駕駛汽車的連續傳感器讀數,都需要近乎實時的處理與分析。
- 多樣性(Variety):數據類型極其豐富,遠超傳統的結構化數據庫。它包括結構化數據(如表格)、半結構化數據(如XML、JSON日志)和非結構化數據(如文本、圖像、音頻、視頻),這給存儲、管理和分析帶來了巨大挑戰。
- 價值(Value):這是大數據的終極目標。海量數據本身價值密度低,需要通過先進的分析技術,從看似無關的海量信息中“沙里淘金”,挖掘出深刻的洞察、模式與規律,以支持商業決策、科學發現和社會治理。
- 真實性(Veracity,或稱準確性):數據的質量、可信度和準確性至關重要。不準確、不完整或有偏見的數據會導致錯誤的結論,即“垃圾進,垃圾出”。
二、 大數據如何賦能人工智能
人工智能,特別是其分支機器學習和深度學習,其核心是從數據中學習規律。大數據為AI提供了不可或缺的“訓練場”和“測試場”。
- 海量訓練數據:模型精度的基石。深度學習模型,如圖像識別、自然語言處理模型,其性能高度依賴于訓練數據的規模和質量。大數據提供了前所未有的、覆蓋各種場景和案例的樣本,使得AI模型能夠學習到更復雜、更細微的模式,從而大幅提升其準確性和泛化能力。沒有大數據,當前的AI突破幾乎不可能實現。
- 燃料迭代與優化。AI模型不是一成不變的,需要持續學習和優化。大數據流(如用戶行為數據、系統運行日志)為模型的在線學習、A/B測試和反饋循環提供了源源不斷的素材,使AI系統能夠適應變化、不斷進化。
- 發現隱藏關聯與洞察。通過大數據分析技術(如數據挖掘、關聯分析),可以在看似無關的龐雜數據中發現人類難以察覺的深層關聯。這些關聯可以作為特征輸入AI模型,或直接為決策提供支持,從而拓展AI的認知邊界。例如,零售業通過分析顧客的購買記錄、瀏覽歷史和地理位置等大數據,可以構建精準的推薦系統(一種AI應用)。
- 提供驗證與評估場景。一個AI算法或模型是否有效,需要在真實、復雜的大數據環境中進行驗證。大數據提供了近乎無窮的測試用例,幫助開發者評估模型的魯棒性、公平性和實用性。
三、 協同共進:大數據與AI的融合閉環
大數據與人工智能的關系并非單向供給,而是形成了一個強大的協同增強閉環:
- 大數據驅動AI:如上所述,數據是AI學習的食糧。
- AI提升大數據處理能力:面對海量、多源、高速的數據,傳統處理方法已力不從心。AI技術,特別是機器學習算法,被廣泛應用于大數據處理的各個環節:
- 智能數據清洗與整合:自動識別并處理缺失值、異常值和重復數據。
- 自動化特征工程:從原始數據中自動提取對預測任務有用的特征。
- 智能分析與洞察生成:自動進行聚類、分類、預測和異常檢測,將數據轉化為 actionable insight(可執行的洞察)。
- 優化數據管理:AI可以優化數據庫索引、查詢路徑和數據存儲策略。
這個閉環使得系統能夠更高效地處理數據,從數據中獲得更優的模型,再用更優的模型去處理新的數據,形成螺旋式上升的能力增強。
###
總而言之,大數據是人工智能賴以生存和發展的土壤。它不僅是“量”的積累,更是“質”的多元與動態體現。理解大數據的“4V/5V”特征,是把握其價值的關鍵。在當下,我們正見證著由大數據驅動的人工智能革命,從智慧城市、精準醫療到智能制造、個性化服務,其應用已滲透到社會的方方面面。隨著數據規模的持續爆炸和AI技術的不斷突破,二者的深度融合必將釋放出更為驚人的潛力,持續重塑我們的世界。因此,在談論人工智能的未來時,我們絕不能忽視其背后那個龐大、復雜且充滿活力的大數據世界。